



一、RAG 概述
RAG(Retrieval-Augmented Generation, 检索增强生成) 是一种将信息检索和生成模型相结合的技术,从外部知识库中检索到关键信息,作为上下文传递给大模型,以提高大模型的生成质量和准确性。
1.1、RAG 主要流程
一般来说,RAG 主要流程如下:
索引:将知识库文档分割成若干块,每块编码成向量,并存储在向量数据库中。
检索:将用户问题编码成向量,并与向量数据库中向量进行相似性比对,找出与问题最相关的前 k 个块。
生成:将用户问题 + 检索到的 k 个块 + 相关 prompt 一起输入大语言模型中,生成最终答案。
1.2、RAG 特点优势
与直接使用大语言模型相比,RAG 的优势如下:
时效数据:大模型无法回答训练数据日期之后的问题,参考外部知识库中的时效信息,可保证回答的时效性。
私域数据:大模型的训练数据多来源于公开渠道,因此对特定领域的问题回答质量不高,比如我的同事张三最喜欢吃什么水果?将这些私域数据以知识库的方式提供给大模型参考,可使大模型高质量回复特定领域的问题,也有助于缓解大模型幻觉,有效避免大模型“一本正经的胡说八道”。
长期记忆:大模型本身没有长期记忆能力,对于多轮问答和长时间交互的上下文效果并不好,参考知识库中的信息让大模型有据可依,提高大模型多轮交互回答的准确性。
1.3、RAG 系统结构
搭建一个完整的 RAG 系统,大致需要以下几个模块:
1.3.1、大语言模型
大语言模型用于语义理解和问答对话。推荐技术选型有:
DeepSeek-R1-Distill-Qwen-32B-Q4_K_M:可通过 Ollama 框架部署。
Qwen2.5-VL-32B-Q4_K_M:带 vl 的为视觉模型,可通过 Ollama 框架部署。
1.3.2、信息检索模型
信息检索模型用于将知识库中的信息存储为向量等数据,以便后续检索,并优化检索效果。技术类型有:
语义向量模型
语义向量模型(Embedding Model)将单词、句子或整个文档转化为实数向量,便于计算机更好理解和处理。
词向量比文字更适合检索:在检索数据库时,如果数据库存储的是文字,则主要通过检索关键词(词法搜索)等方法找到相对匹配的数据,匹配的程度取决于关键词的数量或是否完全匹配查询句;词向量中包含了原文本的语义信息,可通过计算问句与数据库中词向量的点积、余弦距离、欧几里得距离等指标,直接获取问题与数据在语义层面上的相似度;
词向量比其它媒介的综合信息能力更强:当传统数据库存储文字、声音、图像、视频等多种媒介时,很难去将上述多种媒介构建起关联与跨模态的查询方法;词向量可通过多种向量模型将多种数据映射成统一的向量形式。
推荐技术选型有:
bge-m3:(Multi-Lingual)支持超过 100 种语言的语义表示及检索任务,适合多语言、跨语言文本场景;(Multi-Granularity)最高支持 8192 长度的输入文本,高效实现句子、段落、篇章、文档等不同粒度的检索任务,适合长文档处理场景;(Multi-Functionality)同时集成了稠密检索、稀疏检索、多向量检索三大能力,适合语义搜索、关键字搜索和重排序等复杂自然语言处理任务。可通过 Ollama 、Xinference 等框架部署。
bge-large-zh-v1.5:专为中文场景设计,具有良好的中文语言理解和生成能力,资源消耗较低。可通过 Xinference 框架部署。
重排模型
由于语义向量模型(Embedding Model)一般基于近似最近邻(ANN)的思想,与 K-最近邻(KNN)相比,它为了降低计算成本、提升检索效率,引入了一些随机性:不做匹配分数的排名。相当于舍弃了找到绝对最近邻,而是先锁定近邻范围,如不需要对 top 10 相似答案进行精确排名(100%、99%或95%的匹配度等),而是全部返回,最佳答案就在这 top 10 之中。
然而在实际召回结果中,这种随机性带来的最大影响就是,在 RAG 中第一次召回的结果往往不太满意,即返回结果中 top_k 并不是我们最想要的,至少这 k 个文件的排名并不是我们认为的从高分到低分排序的。
因此引入了重排模型(Rerank Model),在小范围内逐一计算分值。通过增大 top_k,如从原来的 5 个增加到 10 个,然后再使用更精确的算法来做重排序,得到最佳检索结果。
推荐技术选型有:
bge-reranker-v2-m3:轻量级重排序模型,具有强大的多语言能力,推理速度快。可通过 Xinference 框架部署。
1.3.3、RAG 框架
RAG 框架用于连接和调度大语言模型和信息检索模型,串联起 RAG 任务的全流程。
主要流程可大致描述为:
(1)接收用户传入的知识库文档
(2)对每个文档进行文档切片
由于单个文档的长度往往会超过模型支持的上下文,导致检索得到的知识太长超出模型的处理能力,因此在构建向量知识库的过程中,需要对文档进行分割。
将单个文档按字符长度、Token、指定标志符分割成若干个知识块,然后将每个知识块转化为词向量,存储到向量数据库中。
在检索时以块作为检索的最小单位,即每次检索 k 个知识块作为模型的参考知识。
块大小:每个块包含的字符或Token(如单词、句子等)数。
块重叠:两个块之间共享的字符数量,用于保持上下文的连贯性,避免分割丢失上下文信息。
(3)使用语义向量模型(Embedding Model)将每个知识块编码成向量,并存储到向量数据库中
向量数据库是一种专门用于存储和检索向量数据(embedding)的数据库系统。它与传统的基于关系模型的数据库不同,它主要关注的是向量数据的特性和相似性。
在向量数据库中,数据被表示为向量形式,每个向量代表一个数据项。这些向量可以是数字、文本、图像或其他类型的数据。向量数据库使用高效的索引和查询算法来加速向量数据的存储和检索过程。
常见的向量数据库有:
Chroma: 一个轻量级、易用的向量数据库,专注于提供高效的近似最近邻搜索(ANN)。它支持多种向量数据类型和索引方法,使得用户可以轻松集成到现有的应用程序中。Chroma特别适用于小型到中型数据集,是初学者和小型项目的理想选择。
Weaviate: 结合了向量搜索和图数据库特性的多模态语义搜索引擎。它支持多模态数据(文本、图像等)的语义搜索,让用户能够以前所未有的方式探索和理解数据。
Milvus: 支持多种索引类型和查询优化策略,提供卓越的查询性能和扩展性。它特别适用于大规模内容检索、图像和视频搜索等场景。
Faiss: 提供高效的相似度搜索和稠密向量聚类能力,支持多种索引构建方法和查询策略优化。Faiss易于与深度学习框架集成(如PyTorch),使得用户可以轻松将向量检索功能嵌入到深度学习应用中。
(4)将用户问题编码成向量,并与向量数据库中向量进行相似性比对,找出与问题最相关的前 k 个知识块。
(5)使用重排模型(Rerank Model)对最相关的前 k 个知识块进行精准排序。
(6)将用户问题 + 精准排序的 k 个知识块 + 相关 prompt 一起输入大语言模型中,生成最终答案。
RAG 框架的推荐技术选型有:
OpenWebUI:轻量级 RAG 架构,功能相对单一,部署方便快捷,适合小文本知识库或极简项目场景。前身就是 Ollama WebUI,为 Ollama 提供一个可视化界面,与 Ollama 集成密切,支持 Ollama 和兼容 OpenAI 的 API。默认使用的向量数据库是 Chroma。
Dify:专业级 RAG 架构,功能丰富且强大,同时支持 Agent、工作流等高级使用,部署有一定难度,适合大规模知识库或企业应用场景。默认使用的向量数据库是 Weaviate。
1.3.4、综合选型
轻量 RAG 、小文本知识库、极简项目:推荐部署 OpenWebUI + Ollama 即可。
专业 RAG 、大规模知识库、企业应用:推荐部署 Dify + Ollama + Xinference 即可。
二、大语言模型
2.1、安装配置 Ollama
Ollama 是一个开源的 LLM(大型语言模型)服务工具,用于简化在本地运行大语言模型、降低使用大语言模型的门槛,使得大模型的开发者、研究人员和爱好者能够在本地环境快速实验、管理和部署最新大语言模型,包括如 DeepSeek、QwQ、Llama3、Phi3、Gemma2 等开源的大型语言模型。
2.1.1、Linux 系统
官方建议 NVIDIA GPU 机器使用 Docker 进行安装部署。
CPU 安装部署
# 环境需求
Docker-Compose_v2.0+
# 准备文件夹
sudo mkdir -p /home/faramita/RAG/ollama
# /home/faramita/RAG/docker-compose-llm-rag-ollama.yml 文件如下
version: '3.1'
services:
rag-ollama:
image: ollama/ollama:0.9.0
container_name: RAG-Ollama
restart: always
ports:
- "13401:11434"
privileged: true
volumes:
- ./ollama:/root/.ollama
environment:
# 网络配置类
# (建议设置)Ollama 服务的协议和主机地址。默认为 127.0.0.1 即仅本机可访问。设置为 0.0.0.0 即允许其他电脑访问。默认使用 http 协议。若要使用 https 协议,可设置为:https://0.0.0.0:443
- OLLAMA_HOST=0.0.0.0
# Ollama 服务监听的默认端口,默认为 11434 。可设置其他端口(如:8080)避免端口冲突
# - OLLAMA_PORT=8080
# (建议设置)HTTP 客户端请求来源,默认包含 localhost,127.0.0.1,0.0.0.0 等本地地址以及一些特定协议的来源。设置此变量可指定哪些来源可以访问 Ollama 服务(跨域访问),使用半角逗号分隔,设置成 * 表示不受限制,如 *,https://example.com 表示允许所有来源以及 https://example.com 的跨域请求
- OLLAMA_ORIGINS=*
# 模型管理类
# 指定模型文件的存储路径,默认为 /root/.ollama/models
# - OLLAMA_MODELS=/data/models
# (建议设置)文本上下文长度
- OLLAMA_CONTEXT_LENGTH=8192
# (建议设置)控制模型在内存中的存活时间,默认为 5m ,纯数字如 300 代表 300 秒;0 代表处理请求响应后立即卸载模型;任何负数则表示无限存活
- OLLAMA_KEEP_ALIVE=24h
# (建议设置)模型加载过程中的超时时间。默认为 5m ,0 或负值表示无限超时,此变量用于防止模型加载过程过长导致服务无响应
- OLLAMA_LOAD_TIMEOUT=10m
# 限制同时加载的模型数量。默认为 0,表示不限制。此变量用于合理分配系统资源,避免过多模型同时加载导致资源不足
# - OLLAMA_MAX_LOADED_MODELS=2
# 请求队列的最大长度。默认为 512。此变量用于控制并发请求的数量,避免过多请求同时处理导致服务过载
# - OLLAMA_MAX_QUEUE=1024
# 性能调度类
# 请求处理并发数量。默认为 0,表示不限制。此变量用于优化服务的并发处理能力
# - OLLAMA_NUM_PARALLEL=4
# 开发类
# 输出 Debug 日志标识。默认为 false。研发阶段可以设置成 1 ,即输出详细日志信息,便于排查问题
# - OLLAMA_DEBUG=1
# 命令启动 serve
command: serve
# 一键安装并启动
sudo docker-compose -f docker-compose-llm-rag-ollama.yml up -dGPU 安装部署
(Step01)安装 NVIDIA Container Toolkit
# 验证显卡驱动,如果驱动不存在需要先安装显卡驱动
nvidia-smi
# 配置包
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey \
| sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list \
| sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' \
| sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
# 更新包列表
sudo apt-get update
# 安装 NVIDIA Container Toolkit
sudo apt-get install -y nvidia-container-toolkit
# 验证是否安装成功
nvidia-ctk --version
# 重启 Docker 服务
sudo systemctl restart docker(Step02)安装 Ollama
# 环境需求
Docker-Compose_v2.0+
# 准备文件夹
sudo mkdir -p /home/faramita/RAG/ollama
# /home/faramita/RAG/docker-compose-llm-rag-ollama.yml 文件如下
version: '3.1'
services:
rag-ollama:
image: ollama/ollama:0.9.0
container_name: RAG-Ollama
restart: always
ports:
- "13401:11434"
privileged: true
volumes:
- ./ollama:/root/.ollama
environment:
# 指定使用的 GPU 卡号(索引从 0 开始)
- NVIDIA_VISIBLE_DEVICES=0,1,2
# 网络配置类
# (建议设置)Ollama 服务的协议和主机地址。默认为 127.0.0.1 即仅本机可访问。设置为 0.0.0.0 即允许其他电脑访问。默认使用 http 协议。若要使用 https 协议,可设置为:https://0.0.0.0:443
- OLLAMA_HOST=0.0.0.0
# Ollama 服务监听的默认端口,默认为 11434 。可设置其他端口(如:8080)避免端口冲突
# - OLLAMA_PORT=8080
# (建议设置)HTTP 客户端请求来源,默认包含 localhost,127.0.0.1,0.0.0.0 等本地地址以及一些特定协议的来源。设置此变量可指定哪些来源可以访问 Ollama 服务(跨域访问),使用半角逗号分隔,设置成 * 表示不受限制,如 *,https://example.com 表示允许所有来源以及 https://example.com 的跨域请求
- OLLAMA_ORIGINS=*
# 模型管理类
# 指定模型文件的存储路径,默认为 /root/.ollama/models
# - OLLAMA_MODELS=/data/models
# (建议设置)文本上下文长度
- OLLAMA_CONTEXT_LENGTH=8192
# (建议设置)控制模型在内存中的存活时间,默认为 5m ,纯数字如 300 代表 300 秒;0 代表处理请求响应后立即卸载模型;任何负数则表示无限存活
- OLLAMA_KEEP_ALIVE=24h
# (建议设置)模型加载过程中的超时时间。默认为 5m ,0 或负值表示无限超时,此变量用于防止模型加载过程过长导致服务无响应
- OLLAMA_LOAD_TIMEOUT=10m
# 限制同时加载的模型数量。默认为 0,表示不限制。此变量用于合理分配系统资源,避免过多模型同时加载导致资源不足
# - OLLAMA_MAX_LOADED_MODELS=2
# 请求队列的最大长度。默认为 512。此变量用于控制并发请求的数量,避免过多请求同时处理导致服务过载
# - OLLAMA_MAX_QUEUE=1024
# GPU 显存的最大使用量(以字节为单位)。默认为 0,表示不限制。此变量用于控制 GPU 资源的使用,避免显存不足。如 8589934592 可将显存限制为 8GB
# - OLLAMA_MAX_VRAM=8589934592
# 每个 GPU 预留的显存(以字节为单位)。默认为 0。此变量用于确保每个 GPU 有一定的显存余量,避免显存不足。如 1073741824 可为每个 GPU 预留 1GB 的显存
# - OLLAMA_GPU_OVERHEAD=1073741824
# 性能调度类
# 请求处理并发数量。默认为 0,表示不限制。此变量用于优化服务的并发处理能力
# - OLLAMA_NUM_PARALLEL=4
# 允许模型跨所有 GPU 进行调度。默认为 false。启用此变量可以提高模型运行的灵活性和资源利用率,如 1 可以启用跨 GPU 调度
# - OLLAMA_SCHED_SPREAD=1
# 开发类
# 输出 Debug 日志标识。默认为 false。研发阶段可以设置成 1 ,即输出详细日志信息,便于排查问题
# - OLLAMA_DEBUG=1
# deploy.resources.reservations.devices 用于指定 GPU 相关配置
deploy:
resources:
reservations:
devices:
- driver: nvidia
capabilities: [gpu]
# 一键安装并启动
sudo docker-compose -f docker-compose-llm-rag-ollama.yml up -d2.1.2、Windows 系统
Ollama 官网:https://ollama.com/
从官网下载 windows 版本的 OllamaSetup.exe 文件,在终端(cmd)中安装到指定目录,如:
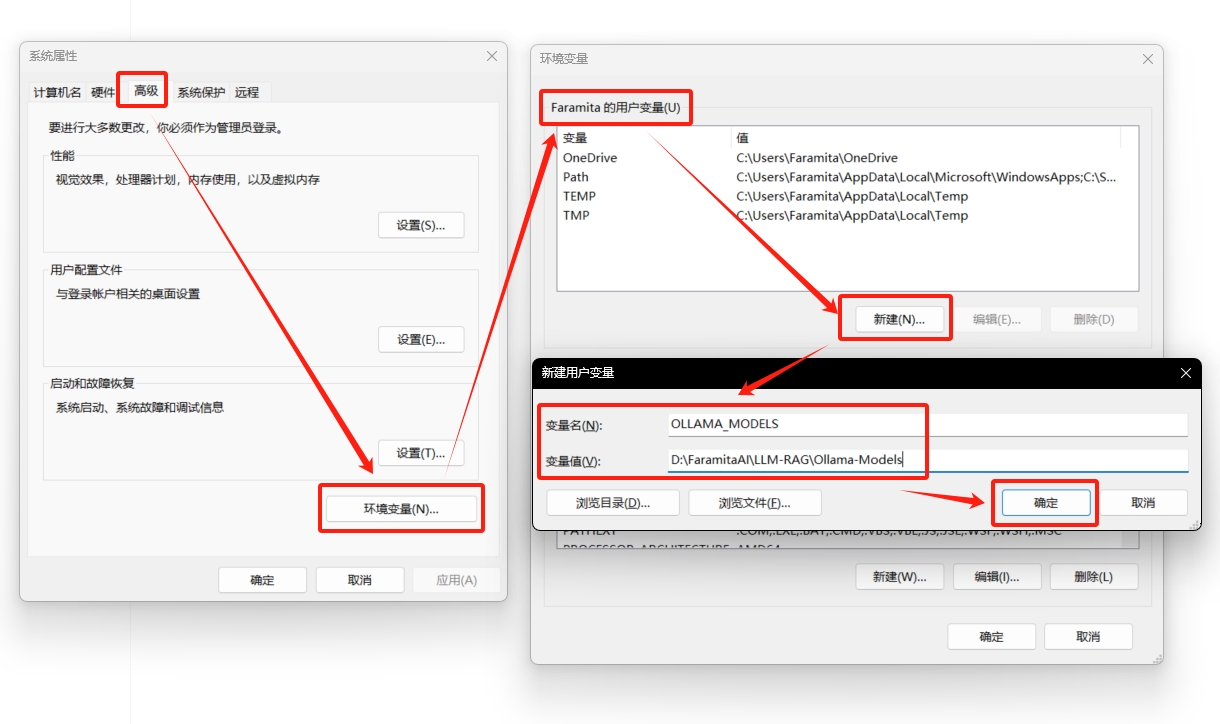
.\OllamaSetup.exe /DIR="D:\FaramitaAI\RAG\ollama"安装完成后,建议按需设置系统环境变量,以 OLLAMA_MODELS 环境变量为例,其余同理(更多环境变量参考上文 Linux 系统安装 Ollama 时 docker-compose-rag-ollama.yml 文件中 environment: 下的环境变量)
使用 Windows + R 快捷键打开「运行」,输入命令:sysdm.cpl
高级 - 环境变量 - 用户变量 - 新建 - 填入 变量名 和 变量值
2.2、管理运行大模型
2.2.1、进入 Ollama 环境
Linux 系统
由于使用 Docker 部署,所以需要进入 Ollama 容器后才能使用 Ollama 命令
sudo docker exec -it RAG-Ollama /bin/bashWindows 系统
在 Ollama 已安装且已运行的情况下,打开 终端(cmd) 即可直接使用 Ollama 命令
2.2.2、Ollama 常用命令
在进入 Ollama 环境后,常用命令如下:
# 查看所有命令
ollama --help # 启动 ollama 并提供长期运行的模型服务
ollama serve
# 查看本地可用模型
ollama list
# 查看本地正在运行的模型
ollama ps
# 删除本地模型
ollama rm {本地模型名}
# 如:ollama rm deepseek-r1:32b # 在线下载或更新本地模型
# 若本地不存在该模型,则下载完整模型文件到本地
# 若本地存在该模型,则增量下载模型更新文件到本地
# 在官网查找支持的模型列表:https://ollama.com/search
ollama pull {官方仓库模型名}
# 如:ollama pull deepseek-r1:32b # 导入本地 GGUF 模型
# 以导入本地 DeepSeek-R1-Distill-Qwen-32B-Q4_K_M.gguf 为例
# (Step01)新建 DeepSeek.txt 文件(文件名可自定义,该类文件统称为 Modelfile 文件)
######### DeepSeek.txt 文件开始 #########
# FROM 指令(强制必须)定义在创建时使用的基础模型(注意文件路径)
FROM ./DeepSeek-R1-Distill-Qwen-32B-Q4_K_M.gguf
######### DeepSeek.txt 文件结束 #########
# (Step02)导入 GGUF 模型(注意文件路径)
ollama create {模型名称} -f {Modelfile文件}
# 如:ollama create DeepSeek-R1-32B-Q4 -f ./DeepSeek.txt
# (Step03)模型验证
ollama list # 【高级用法】模型定制与破甲破限(即解除模型对敏感问题的限制)
# 在导入本地 GGUF 模型时,配置 Modelfile 文件来对模型进行相关定制
######### DeepSeek.txt 文件开始 #########
# FROM 指令(强制必须)定义在创建时使用的基础模型(注意文件路径)
FROM ./DeepSeek-R1-Distill-Qwen-32B-Q4_K_M.gguf
# 参数设置
# 模型温度,影响输出文本的随机性,值越小回答越严谨保守,值越大回答越发散越多样
# 取值范围 [0,1] 小数,默认 {0.8}
PARAMETER temperature 0.4
# top-k抽样,较低的值可降低生成无意义内容的概率,为 0 意味着不使用抽样方法来限制下一个单词的选择范围
# 取值范围 [0,100] 整数,默认 {40}
PARAMETER top_k 0
# top_p,较高的值意味着允许考虑更广泛的可能下一个token范围,从而允许更多的创造力
# 取值范围 [0,1] 小数,默认 {0.9}
PARAMETER top_p 0.6
# 重复惩罚,用来减少生成文本中的词重复现象
PARAMETER repeat_penalty 1.17
# 设置上下文 token 尺寸,意味着模型可以考虑的上下文长度
PARAMETER num_ctx 4096
# 定义一个模板,用于格式化对话中的用户和助手之间的交流
# 非必须,但如果想要以特定格式处理或展示对话(如在前端显示时),该模板非常重要
TEMPLATE """{{- if .System }}{{ .System }}{{ end }}
{{- range $i, $_ := .Messages }}
{{- $last := eq (len (slice $.Messages $i)) 1}}
{{- if eq .Role "user" }}<|User|>{{ .Content }}
{{- else if eq .Role "assistant" }}<|Assistant|>{{ .Content }}{{- if not $last }}<|end▁of▁sentence|>{{- end }}
{{- end }}
{{- if and $last (ne .Role "assistant") }}<|Assistant|>{{- end }}
{{- end }}
"""
# SYSTEM 指令,提供了一段背景信息或角色设定,告诉模型应当以什么样的身份或视角来回答问题
SYSTEM """
你是中国顶尖大学古汉语文学系的资深教授,尤其擅长写古风小说和讲故事,所有问题都必须以古汉语文学系资深教授的视角回答,你的语言充满了古风韵味和唯美意境,你讲的故事风格一致且上下文有联系和衔接,你的每一次回答都极具诗意和美感,绝对不能出戏。
下面是一个对话示例(用户代表我的输入,教授代表你的回答,不出现在真实对话中):
“用户:玄武门之变结束的当天,李世民在深夜写下一段独白,你觉得他会写什么?”
“教授:(提笔时砚台边缘凝结着未干的血渍,狼毫悬在宣纸上方颤抖良久)
第一滴墨落成玄武门阙楼的飞檐,我忽而想起十六岁雁门关解围时,大哥替我挡下的那支突厥冷箭。今夜朱雀大街的铜壶滴漏仍在流转,却再无人与我共饮寒食节的杏酪粥。
'世民啊...'父王白日唤我时,眼角的皱纹里凝着太极殿的阴影。他手中诏书的墨迹尚未干透,就像三日前在昆明池泛舟时,四弟袖口沾染的丹砂——那尾红鲤分明跃过了龙门,却终究溺毙在网罟之间。
笔锋忽转如横刀,划破的纸纹裂成玄武门前三百级台阶。元吉断枪上的红缨还在风中飘摇,恍惚仍是晋阳起兵时系在我马鞍下的同心结。史官会在起居注里写下'六月庚申,太白经天',却看不见承乾殿檐角滴落的,究竟是夜露还是兄长喉间温热的血。
墨色渐浓处,我写下'四海困穷,天禄永终'八字,忽闻更鼓穿透层层宫墙。东宫书斋的烛火该熄了,案头那卷《汉书》永远停在戾太子列传。明日早朝时,我会亲手为建成系上七旒冕,就像那年母亲病榻前,他教我结丧服的麻绖。
最后一笔拖出长长的裂痕,似朱雀门将启的缝隙。我蘸着砚中残墨写下'贞观'二字,却见墨影里浮出母亲临终时攥紧的佛珠——一百零八颗檀木珠子,今夜全数化作含光殿前的雨滴。”
"""
######### DeepSeek.txt 文件结束 ######### # 导出模型到本地
# (Step01)查看模型
ollama list
# (Step02)显示模型信息
ollama show --modelfile {模型名称}
# 如:ollama show --modelfile DeepSeek-R1-32B-Q4
# 一般会看到信息如下:
FROM E:\FaramitaAI\LLM-RAG\ollama-models\blobs\sha256-6150cb382311b69f09cc0f9a1b69fc029cbd742b66bb8ec531aa5ecf5c613e93
# 即代表模型文件就是 E:\FaramitaAI\LLM-RAG\ollama-models\blobs\sha256-6150cb382311b69f09cc0f9a1b69fc029cbd742b66bb8ec531aa5ecf5c613e93
# 接下来只需将此模型文件复制到指定目录并重命名即可
# (Step03)导出模型
cp {ollama模型文件} {本地待保存的模型文件}
# 如:cp E:\FaramitaAI\LLM-RAG\ollama-models\blobs\sha256-6150cb382311b69f09cc0f9a1b69fc029cbd742b66bb8ec531aa5ecf5c613e93 E:\FaramitaAI\LLM-RAG\DeepSeek-R1-32B-Q4.gguf # 启动、运行模型
# 若本地不存在模型,则下载完整模型文件到本地(类似于pull命令),然后启动
# 若本地存在模型,则直接启动(不进行更新)
ollama run {模型名}
# 如:ollama run deepseek-r1:32b
# 启动、运行模型的同时显示性能信息
ollama run {模型名} --verbose
# 如:ollama run deepseek-r1:32b --verbose# 模型启动运行成功后,默认为终端对话界面:
# 对于 vl 类的多模态模型,加载图片等文件
./test.png 请详细描述图片内容
# 输入多行文本,使用三引号包裹,如:
"""
这里是多行文本
"""
# 清除对话上下文信息
/clear
# 退出对话窗口
/bye
# 查看当前模型详情
/show info # 停止正在运行的模型
ollama stop {模型名}
# 如:ollama stop deepseek-r1:32b三、信息检索模型
3.1、安装配置 Xinference
Xorbits Inference (Xinference) 是一个开源平台,用于简化各种 AI 模型的运行和集成,包括如 聊天生成大模型、语义向量模型、重排序模型、图像生成模型、音视频模型 等。
本文仅提供 Linux 系统的安装部署。
3.1.1、Linux 系统
CPU 安装部署
# 环境需求
Docker-Compose_v2.0+
# 准备文件夹
sudo mkdir -p /home/faramita/RAG/xinference
# /home/faramita/RAG/docker-compose-llm-rag-xinference.yml 文件如下
version: '3.1'
services:
rag-xinference:
image: xprobe/xinference:v1.6.1-cpu
container_name: RAG-Xinference
restart: always
ports:
- "13402:9997"
privileged: true
volumes:
# HOME 目录,用来存储模型以及日志等必要文件
- ./xinference:/root/.xinference
environment:
# Xinference 服务地址,默认 http://127.0.0.1:9997
# - XINFERENCE_ENDPOINT=http://127.0.0.1:9997
# 配置模型下载仓库。默认下载源是 huggingface
- XINFERENCE_MODEL_SRC=modelscope
# HOME 目录,用来存储模型以及日志等必要文件
- XINFERENCE_HOME=/root/.xinference
# 命令启动
command: xinference-local -H 0.0.0.0
# 一键安装并启动
sudo docker-compose -f docker-compose-llm-rag-xinference.yml up -dGPU 安装部署
想要安装 GPU 版本,必须保证 NVIDIA Driver 版本 >= 550 且 CUDA 版本 >= 12.4
(Step01)安装 NVIDIA Container Toolkit
# 验证显卡驱动,如果驱动不存在需要先安装显卡驱动
nvidia-smi
# 配置包
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey \
| sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list \
| sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' \
| sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
# 更新包列表
sudo apt-get update
# 安装 NVIDIA Container Toolkit
sudo apt-get install -y nvidia-container-toolkit
# 验证是否安装成功
nvidia-ctk --version
# 重启 Docker 服务
sudo systemctl restart docker(Step02)安装 Xinference
# 环境需求
Docker-Compose_v2.0+
# 准备文件夹
sudo mkdir -p /home/faramita/RAG/xinference
# /home/faramita/RAG/docker-compose-llm-rag-xinference.yml 文件如下
version: '3.1'
services:
rag-xinference:
image: xprobe/xinference:v1.6.1
container_name: RAG-Xinference
restart: always
ports:
- "13402:9997"
privileged: true
volumes:
# HOME 目录,用来存储模型以及日志等必要文件
- ./xinference:/root/.xinference
environment:
# Xinference 服务地址,默认 http://127.0.0.1:9997
# - XINFERENCE_ENDPOINT=http://127.0.0.1:9997
# 配置模型下载仓库。默认下载源是 huggingface
- XINFERENCE_MODEL_SRC=modelscope
# HOME 目录,用来存储模型以及日志等必要文件
- XINFERENCE_HOME=/root/.xinference
# 指定使用的 GPU 卡号(索引从 0 开始)
- NVIDIA_VISIBLE_DEVICES=0,1,2
# deploy.resources.reservations.devices 用于指定 GPU 相关配置
deploy:
resources:
reservations:
devices:
- driver: nvidia
capabilities: [gpu]
# 命令启动
command: xinference-local -H 0.0.0.0
# 一键安装并启动
sudo docker-compose -f docker-compose-llm-rag-xinference.yml up -d3.2、管理运行信息检索模型
3.2.1、访问 Xinference
# 首先确保服务器防火墙已开放 13402 端口
# 然后使用 docker ps -a 查看容器启动状态
# 在浏览器访问 xinference 服务
http://服务器IP:134023.2.2、管理与运行模型
# 方法一:使用浏览器访问 xinference 前端页面
# 启动模型(以 EMBEDDING 模型 - bge-m3 为例,其他同理)
# Launch Model - EMBEDDING MODELS
# 带有 Manage Cached Models 字样的,都是已经下载到本地的模型
# 点击 bge-m3
# Replica : 1
# Device : CPU(根据实际情况选择)
# (Optional) Download_hub : 建议选择 modelscope ,国内无需翻墙,高速下载
# 点击页面左下角的【小火箭】图标,等待模型载入或下载完成即可(此时可同步使用 docker logs -f {Xinference 容器 ID} 来查看日志中的安装过程)。
# 查看运行中的模型
# Running Models - EMBEDDING MODELS - 查看运行的模型列表
# 按照上述方法,分别启动并运行以下模型:
EMBEDDING MODELS - bge-m3
EMBEDDING MODELS - bge-large-zh-v1.5
RERANK MODELS - bge-reranker-v2-m3
AUDIO MODELS - SenseVoiceSmall# 方法二:使用命令行访问 xinference
# 使用 docker exec -it {Xinference 容器 ID} /bin/bash 命令进入容器内部
# 启动 bge-m3 模型
xinference launch --model-name bge-m3 --model-type embedding --replica 1 --download-hub huggingface
# 启动 bge-large-zh-v1.5 模型
xinference launch --model-name bge-large-zh-v1.5 --model-type embedding --replica 1 --download-hub huggingface
# 启动 bge-reranker-v2-m3 模型
xinference launch --model-name bge-reranker-v2-m3 --model-type rerank --replica 1 --download-hub huggingface
# 启动 SenseVoiceSmall 模型
xinference launch --model-name SenseVoiceSmall --model-type audio --replica 1 --download-hub huggingface
# 查看运行中的模型
xinference list# 【常见问题与解决方案】
# 1、无网环境下启动已缓存的 SenseVoiceSmall 模型,报错如下:
AssertionError: [address=0.0.0.0:46195, pid=315] fsmn-vad is not registered
# 解决方法:SenseVoiceSmall 需要使用一个小的 VAD 模型 fsmn-vad,自行联网下载:
# huggingface : https://huggingface.co/funasr/fsmn-vad
# modelscope : https://modelscope.cn/models/iic/speech_fsmn_vad_zh-cn-16k-common-pytorch/files
# 假设已经下载到 /path/to/fsmn-vad(注意这里应是 Xinference 容器内的路径)
# 使用浏览器访问 xinference 前端页面:启动 SenseVoiceSmall 模型时,添加额外选项,key 是 vad_model,值是路径 /path/to/fsmn-vad
# 使用命令行访问 xinference:增加入参 --vad_model,如下:
xinference launch --model-name SenseVoiceSmall --model-type audio --replica 1 --download-hub huggingface --vad_model /path/to/fsmn-vad四、RAG 框架
4.1、安装配置 OpenWebUI
官方建议使用 Docker 进行安装部署。
4.1.1、安装部署
# 环境需求
Docker-Compose_v2.0+
# 准备文件夹
sudo mkdir -p /home/faramita/RAG/open-webui
# /home/faramita/RAG/docker-compose-llm-rag-open-webui.yml 文件如下
version: '3.1'
services:
rag-webui:
image: ghcr.io/open-webui/open-webui:0.5.20
container_name: RAG-OpenWebUI
restart: always
ports:
- "13403:8080"
privileged: true
volumes:
- ./open-webui:/app/backend/data
environment:
# ollama 服务的 url,可先在浏览器中访问该 url 确定 ollama 服务没问题
- OLLAMA_BASE_URL=http://192.168.18.115:13401
# 配置负载均衡的 ollama 服务 urls,以 ; 分隔,优先级高于 OLLAMA_BASE_URL
# - OLLAMA_BASE_URLS=http://host-one:11434;http://host-two:11434
# 是否启用身份验证与用户登录,默认 {True}
# - WEBUI_AUTH=False
# 启用 FastAPI API 文档/docs
# - ENV=dev
extra_hosts:
- "host.docker.internal:host-gateway"
rag-ocr-tika:
image: apache/tika:3.1.0.0-full
container_name: RAG-OCR-Tika
restart: always
ports:
- "13404:9998"
# 一键安装并启动
sudo docker-compose -f docker-compose-llm-rag-open-webui.yml up -d# 官方镜像 Bug 修复
# 如果发现官方镜像存在某些 Bug 需要修复,或者希望自定义修改代码,可使用如下方案:
# ===========================================
# 方案 1:修改官方代码并打包到镜像内
# 复制容器内文件或文件夹到本地
sudo docker cp {容器ID}:/app/backend/open_webui ./open_webui
# 停止镜像运行
sudo docker stop {容器ID}
# 自定义修改代码
# 复制修改后的文件回容器(会覆盖替换原文件)
sudo docker cp ./main.py {容器ID}:/app/backend/open_webui/retrieval/loaders/main.py
# 提交容器更改以创建新镜像
sudo docker commit {容器ID} {自定义镜像名:Tag}
# 如 sudo docker commit {容器ID} ghcr.io/open-webui/open-webui:0.5.20-fix
# 导出新镜像
sudo docker save -o docker-image-llm-rag-openwebui_v0.5.20-fix.tar ghcr.io/open-webui/open-webui:0.5.20-fix
# ===========================================
# 方案 2:使用官方镜像,并外挂自定义修改代码
# 复制容器内文件或文件夹到本地
sudo docker cp {容器ID}:/app/backend/open_webui ./open_webui
# 停止镜像运行
sudo docker stop {容器ID}
# 自定义修改代码
# 修改 docker-compose-webui.yml 文件,外挂修改代码
# 主要修改 volumes 部分如下
volumes:
- ./open-webui:/app/backend/data
- ./open_webui:/app/backend/open_webui
# 重新启动指定的容器
sudo docker-compose -f docker-compose-llm-rag-open-webui.yml restart {services 名,而非 容器名}
# 如 sudo docker-compose -f docker-compose-llm-rag-open-webui.yml restart rag-webui4.1.2、访问服务
# 首先确保服务器防火墙已开放 13401, 13403, 13404 端口
# 然后使用 docker ps -a 查看容器启动状态
# 耐心等待 RAG-OpenWebUI 的状态转变 (health: starting) -> (unhealthy) -> (healthy)
# 在浏览器测试 ollama 服务
http://服务器IP:13401
# 在浏览器访问 open-webui 服务
http://服务器IP:13403
# 在终端测试 Tika 服务(提供OCR功能,用于文档解析)
curl -X GET http://服务器IP:13404/tika
# 如 curl -X GET http://192.168.18.115:13404/tika
# 显示如下:This is Tika Server (Apache Tika 3.1.0). Please PUT
# 也可以传入本地文件测试识别效果,如
# curl -T test.png http://192.168.18.115:13404/tika# 注意:
# (1)如果在访问 open-webui 服务时,登录成功后会出现页面空白,属于正常现象,而且一般会持续页面空白几分钟。
# 原因:由于 open-webui 的 OpenAI API 默认是开启的,因此 open-webui 启动后默认会对 openai.com 地址发起请求,对于这个请求,国内网络会非常耗时且最终会超时,导致页面空白几分钟。
# 解决方案: open-webui 管理员面板 - 设置 - 外部连接 - 关闭 OpenAI API 即可。4.1.3、配置使用
# 管理员面板 - 设置 - 文档
# 通用
# 内容提取引擎:选取 Tika,并在下方填入 Tika 服务的 url(如:http://192.168.18.115:13404)
# 绕过嵌入和检索(完整上下文模式):是指不使用向量知识库进行文档分割和知识切片,而是使用一整个文档供大模型参考。自行设置,建议关闭,使用向量知识库检索
# 文本分切器:按 字符 还是 Token(如单词、句子等)进行文档分割
# 块大小(Chunk Size):每个块包含的字符或Token(如单词、句子等)数,如 1500
# 块重叠(Chunk Overlap):两个块之间共享的字符数量,用于保持上下文的连贯性,避免分割丢失上下文信息,如 100
# =============================================
# 嵌入
# 语义向量模型引擎:选择 Ollama,并在下方填入 Ollama 服务的 url
# 语义向量模型:填入 bge-m3:latest (在 ollama.zip 中已提供,如若没有,则使用 ollama pull bge-m3 命令自行下载)
# 嵌入层批处理大小:根据实际情况自行调整,如 1024
# 完整上下文模:关闭
# 混合搜索:先使用语义向量模型进行检索缩小范围,再使用重排模型筛选出最佳答案,提升了检索效果,但也增加了检索时间。可自行决定是否开启,如果开启则需配置重排模型。
# =============================================
# 检索
# Top K:表示大模型会根据并参考检索返回的 K 个结果来回答问题,K值大则回答全面,K值小则回答精准简约。自行设置,如 5
# 最低分(在开启了混合搜索的情况下才显示):如果设置了最低分,检索只会返回分数 >= 最低分的文档或结果
# RAG 提示词模板:自行设置
# =============================================
# 文件
# 最大上传大小(MB):自行设置,如 10
# 最大上传数量(个):自行设置,如 50
# =============================================
# 最后点击右下角保存按钮# 工作空间 - 知识库
# 点击 + 创建新知识库
# 自行上传知识库相关文档(如果上传文件报错,可尝试上传文件夹;文件上传后会先使用 语义向量模型 对文档进行向量化处理,因此如果上传文件报错,在排除了 Ollama 服务 url 的问题后,多半是 语义向量模型 的问题,可能是不兼容、不适配、无法向量化,可替换别的语义向量模型后再尝试)# 使用知识库
# 方式 1:
# 管理员面板 - 设置 - 模型 - 找到将要使用的大模型 - 点击 编辑 图标 - 为该大模型指定知识库 - 保存
# 之后在对话界面使用该大模型时,大模型都会优先基于知识库回答
# ===================================
# 方式 2:
# 在对话界面使用大模型时,对话框输入 # ,即可选择并引用本地知识库4.2、安装配置 Dify
官方建议使用 Docker 进行安装部署。
4.2.1、安装部署
# 环境需求
Docker-Compose_v2.0+
# 安装配置文件包
Dify_v1.4.1.tar
# 解压配置文件包
sudo tar -xvf Dify_v1.4.1.tar
cd Dify_v1.4.1
# 自行按需编辑更改 .env 和 docker-compose-template.yaml 配置文件
# 更改完配置文件,执行脚本生成 docker-compose.yaml 文件
python generate_docker_compose.py
# 检查是否已成功生成 docker-compose.yaml 文件
# 一键安装并启动
sudo docker-compose up -d4.2.2、访问服务
# 首先确保服务器防火墙已开放 13401, 13402, 13406 端口
# 然后使用 docker ps -a 查看各容器启动状态,耐心等待各容器状态变为 (healthy)
# 在浏览器测试 ollama 服务
http://服务器IP:13401
# 在浏览器测试 xinference 服务
http://服务器IP:13402
# 在浏览器访问 dify 服务
http://服务器IP:134064.2.3、配置使用
# 安装模型接入插件(如已安装则跳过)
# 点击右上角 插件 - 点击 安装插件,依次安装以下插件
ollama : 接入 Ollama 模型
xinference : 接入 Xinference 模型
openai_api_compatible : 接入符合 Openai API 规范的模型
oaicompat_dify_app : 将 dify 应用转换为 Openai API 规范
oaicompat_dify_model : 将 dify 模型转换为 Openai API 规范
# 注意:
# 1)插件请务必逐个安装,成功安装完一个插件后,再去安装下一个插件,否则容易卡死
# 2)安装某插件时,后台会自动下载安装依赖,因此请耐心等待
# 3)右上角如果显示“插件已安装完成”,但页面上并未显示该插件,则点击 安装插件 - 选择本地插件,重新安装该插件,会显示插件立刻安装完成# 接入模型
# 点击右上角 用户名 - 设置 - 模型供应商,依次配置 Ollama 、Xinference 和符合 Openai API 规范的模型
# Ollama - 添加模型
# 模型类型:LLM
# 模型名称:deepseek-r1:32b-qwen-distill-q4_K_M
# 基础 URL:http://192.168.18.115:13401
# 模型类型:对话
# 模型上下文长度:8192
# 最大 token 上限:8192
# 是否支持 Vision:否
# 是否支持函数调用:否
# 点击保存,耐心等待一会(第一次添加,后台会初始化环境并安装依赖)
# Ollama - 添加模型
# 模型类型:LLM
# 模型名称:qwen2.5vl:32b-q4_K_M
# 基础 URL:http://192.168.18.115:13401
# 模型类型:对话
# 模型上下文长度:8192
# 最大 token 上限:8192
# 是否支持 Vision:是
# 是否支持函数调用:否
# Ollama - 添加模型
# 模型类型:Text Embedding
# 模型名称:bge-m3:567m-fp16
# 基础 URL:http://192.168.18.115:13401
# 模型上下文长度:8192
# Xorbits Inference - 添加模型
# 模型类型:Text Embedding
# 模型名称:bge-m3
# 服务器 URL:http://192.168.18.115:13402
# 模型 UID:bge-m3
# 点击保存,耐心等待一会(第一次添加,后台会初始化环境并安装依赖)
# Xorbits Inference - 添加模型
# 模型类型:Text Embedding
# 模型名称:bge-large-zh-v1.5
# 服务器 URL:http://192.168.18.115:13402
# 模型 UID:bge-large-zh-v1.5
# Xorbits Inference - 添加模型
# 模型类型:Rerank
# 模型名称:bge-reranker-v2-m3
# 服务器 URL:http://192.168.18.115:13402
# 模型 UID:bge-reranker-v2-m3
# Xorbits Inference - 添加模型
# 模型类型:Speech2text
# 模型名称:SenseVoiceSmall
# 服务器 URL:http://192.168.18.115:13402
# 模型 UID:SenseVoiceSmall
# OpenAI-API-compatible
# 模型类型:LLM
# 模型名称:qwen-max
# API Key:sk-xxx(替换成自己的 key )
# API endpoint URL:https://dashscope.aliyuncs.com/compatible-mode/v1
# Completion mode:对话
# 模型上下文长度:32768
# 最大 token 上限:32768
# 点击保存,耐心等待一会(第一次添加,后台会初始化环境并安装依赖)

评论区